
Computer vision is rapidly evolving day-by-day. One of the reasons for this is Machine Learning.
This AI technology allows computers and systems to extract meaningful information from digital images, videos, and other visual data, and then operate according to the ML scientists’ guidance to make decisions.
Computer vision is based on convolutional neural networks, and the field of application of this technology is very wide: from recognizing faces in photos on social networks to analyzing medical X-rays of patients and designing human-like masterpieces.
Why Self-Supervised Learning?
Supervised Learning usually requires a large amount of tagged data. At the same time, obtaining such labeled data is a rather expensive and time-consuming task, especially for such complex projects as object detection.
At the same time, untagged data is more widely available. The motivation for self-supervised learning is to learn data from an untagged pool of data, using self-monitoring first, and then fine-tuning the multi-tagged views for a supervised subsequent task. The task can be as simple as image classification, or complex projects such as semantic segmentation, object detection, etc.
Self-Supervised Learning Methods for Computer Vision

Instance Discrimination
Instance Discrimination is the finding of object instances in an image. When recognizing objects, not only the fact of the presence of an object in the image is established, but also its location in the image is determined.
Discrimination such a variety of objects and applications necessitates the use of machine learning and deep learning methods.
Object detection involves the comparison of two or more images when searching for images of unique objects, for example, architectural structures, sculptures, paintings, etc., detection of classes of objects of varying degrees of commonality (cars, animals, furniture, human faces, etc.) in the images. and their subclasses), categorization of scenes (city, forest, mountains, coast, etc.).
Photogrammetry
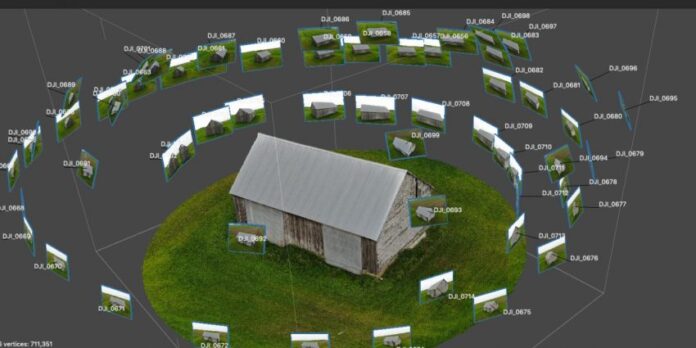
Photogrammetry is the process of creating 3D models from multiple images of a single object photographed from different angles.
This method has long been used in cartography and surveying and has become more popular due to its availability because of the increase in the power of computers. This allowed the use of photogrammetry in other areas:
- creation of geographic information systems;
- environmental protection (study of glaciers and snow cover, soil assessment and study of erosion processes, observation of changes in vegetation cover, study of sea currents);
- design and construction of buildings and structures;
- film industry (combining the game of live actors with computer animation);
- automated building of spatial models of an object using images;
- computer games (creating three-dimensional models of game objects, creating realistic landscapes, etc.).
Obstacle detection
Obstacle detection is used, for example, in ADAS (Adnvanced Driver Assistance System) driver assistance systems, in unmanned aircraft control systems, etc.
ADAS algorithms include the following:
- Lane control,
- Detection of objects in the path of movement and on the sides,
- Recognition of road objects,
- Adaptive cruise control
- All-round overview.
Real-Time Applications of Self-Supervised Learning
In the realm of computer vision, self-supervised learning stands out as a revolutionary technique, enabling models to understand visual data autonomously. This method is permeating various real-time applications, elevating functionalities and capabilities.
For autonomous navigation, interpreting the diverse, dynamic traveling environment is pivotal. Self-supervised learning facilitates the real-time processing of unannotated data, enhancing the reliability and safety of autonomous vehicles by enabling more accurate environment modeling and prediction which can already be seen in ADAS systems.
Within AR, self-supervised learning crafts more interactive, immersive experiences. It understands and interprets the surrounding environment in real-time, allowing AR applications to seamlessly integrate virtual elements with the real world, enhancing user engagement and experience.
In robotics, it’s crucial for machines to comprehend and learn from their environment autonomously. Self-supervised learning empowers robots to make sense of unlabelled data, improving their decision-making processes and adaptability, essential for tasks like object manipulation and navigation.
SLAM

SLAM (Simultaneous Localization And Mapping) is a method of simultaneous localization of objects and building a map in an unknown space or for updating a map in a predetermined space while simultaneously monitoring the current location and the distance traveled. It is used in autonomous vehicles for their orientation in space.
This method is used for spatial reconstruction (Stereo-SLAM) during vehicle movement to create volumetric maps of objects from images from one or more CV cameras.
Flaw detection
CV systems with out-of-pattern recognition are often used to find various defects in materials and products.
Object recognition and localization in a previously shot scene

In addition to the terms “detection” and “recognition”, computer vision technologies also use the terms “classification” and “localization”, as well as “segmentation” of objects.
- Object classification – recognition in the image of one category of the object, usually the most noticeable. This type of recognition is most often used in smartphones equipped with “artificial intelligence”.
- Object localization – the object is not only recognized but also localized in the original image.
- Object detection – the image can contain objects of different classes, which are recognized and localized in the original image.
- Object segmentation – for each object, not only its class and its location are recognized, but also the boundaries of the object in the image are highlighted.
Observer localization and measurement control
Localization algorithms allow you to determine the position of the camera relative to the scene and detect differences in the scene in the historical perspective (the presence of new objects in the scene and changes in the scene coverage) at the point cloud level.
During the localization process, the following tasks are performed:
1. Localization in a sequence of images: find the position of a new image in a previously captured sequence of images;
2. Localization in point clouds (3D models):
- finding the position of the new image in the existing point cloud
- with existing images, sources for a given point cloud;
- find the position of a new image with a textured point cloud, with additional data from GPS (data fusion);
- finding the position of the new point cloud in the existing cloud through the original images;
- Detect changes in images and point clouds.
Example of evaluating the effectiveness of CV implementation

Cognex provides several proprietary cost savings cases for CV systems across a variety of industries.
The renowned automaker implemented a CV system to monitor production equipment, which made it possible to cut several maintenance items for about $ 5,000 a month. The implementation of the CV system paid off in 6 months. The overall performance was estimated at about $ 100,000 per year.
The introduction of robots with computer vision in a manufacturing enterprise made it possible to reduce the cost of an hour of working time by $ 15 per worker. Savings per year amounted to about $ 160,000.
The use of computer vision has enabled a manufacturing facility in the United States to eliminate the use of expensive production line tooling to accurately position workpieces. This enabled the company to save about $ 120,000 a year.


